| Functions | Description | Input | Output |
| setPath | .xlsx 파일이 위치한 경로 설정 | def setPath(self, src : str): | |
| setDF | .xlsx 파일을 통해 DataFrame 생성 | def setDF(self): | |
| add_node | 키워드 노드 추가 | def add_node(self, key): | |
| add_edge | 키워드 간선 추가 | def add_edge(self, u, v): | |
| add_edge_from | 키워드 간선 추가 (iteraitor 사용) | def add_edge_from(self, _list): | |
| getGraph | 그래프 반환 | def getGraph(self): | Object : Networkx Graph |
| make_graph | 그래프 생성 | def make_graph(self, keyword, split_ch, to_csv=False, path="", _range=None): | |
| to_csv | 그래프 CSV로 추출 | def to_csv(self, path : str): | |
| to_betweenness_centrality |
그래프 데이터에 대한 betweenness_centrality 값을 .xlsx로 추출 | def to_betweenness_centrality(self): | |
| to_degree_centrality |
그래프 데이터에 대한 degree_centrality값을 .xlsx로 추출 | def to_degree_centrality(self): | |
| to_eigenvector_centrality |
그래프 데이터에 대한 eigenvector_centrality값을 .xlsx로 추출 | def to_eigenvector_centrality(self): | |
| to_closeness_centrality |
그래프 데이터에 대한 closeness_centrality값을 .xlsx로 추출 | def to_closeness_centrality(self): | |
| drawPlot |
그래프 데이터를 통한 네트워크 이미지 생성 | @staticmethod def drawPlot(G, pos, measure_name, title, percent=100, visible_label=False): |
EX)
g = KN() # 필수
g.setPath('./scopus_precision medicine_1.xlsx') # 엑셀 파일 경로 지정
g.setDF() # 필수
g.make_graph('Author Keywords', ';', True, './test.csv', 100)
############ 추출 열 구분자 CSV 추출여부 추출여부 True시 ROW 지정값
(매트릭스) 저장할 경로 (미지정 시 전체)
------------------------------------
EX)
g.make_graph('Author', ',', 'True', './경로.csv') # scopus_precision medicine_1.xlsx 엑셀 파일에
서 구분자가 ,로 되어 있는 Author 키워드를 뽑아 그래프를 만들 경우 (CSV 추출)
g.make_graph('Author', ',', 'False', '') # scopus_precision medicine_1.xlsx 엑셀 파일에
서 구분자가 ,로 되어 있는 Author 키워드를 뽑아 그래프를 만들 경우(CSV 추출 x)
g.make_graph('Author', ',', 'False', '', 100) # CSV 추출을 하지 않고 100라인에 대해서만 키워드를
뽑아 그래프를 만들 경우
------------------------------------
g.to_betweenness_centrality() # BC 데이터 계산 후 엑셀로 추출됨 (파일이 있는 경로에 자동 생성)
g.to_degree_centrality() # DC 데이터 계산 후 엑셀로 추출됨 (파일이 있는 경로에 자동 생성)
g.to_closeness_centrality() # CC 데이터 계산 후 엑셀로 추출됨 (파일이 있는 경로에 자동 생성)
g.to_eigenvector_centrality() # EC 데이터 계산 후 엑셀로 추출됨 (파일이 있는 경로에 자동 생성)
# 그래프 그리기
------------------------------------
_graph = g.getGraph() # 그래프 받아옴
KN.drawPlot(_graph, nx.spring_layout(_graph), 'Betweenness', 'Betweenness Graph!', 5, True)
######### 그래프 그래프 배치 중심성 타입 그래프의 제목 몇 프로까지 라벨링 여부
제공하는 중심성 타입
- Degree
- Betweenness
- Closeness
- Eigenvector
EX)
- Betweenness centrality의 값들 중 상위 1%의 키워드들만 라벨을 포함한 채 그려라
KN.drawPlot(_graph, nx.spring_layout(_graph), 'Betweenness', 'BC 그래프!', 1, True)
- Degree centrality의 값들 중 상위 5%의 키워드들만 라벨을 포함하지 않은 채 그려라
KN.drawPlot(_graph, nx.spring_layout(_graph), 'Degree', 'DC 그래프!', 5, False)
결과
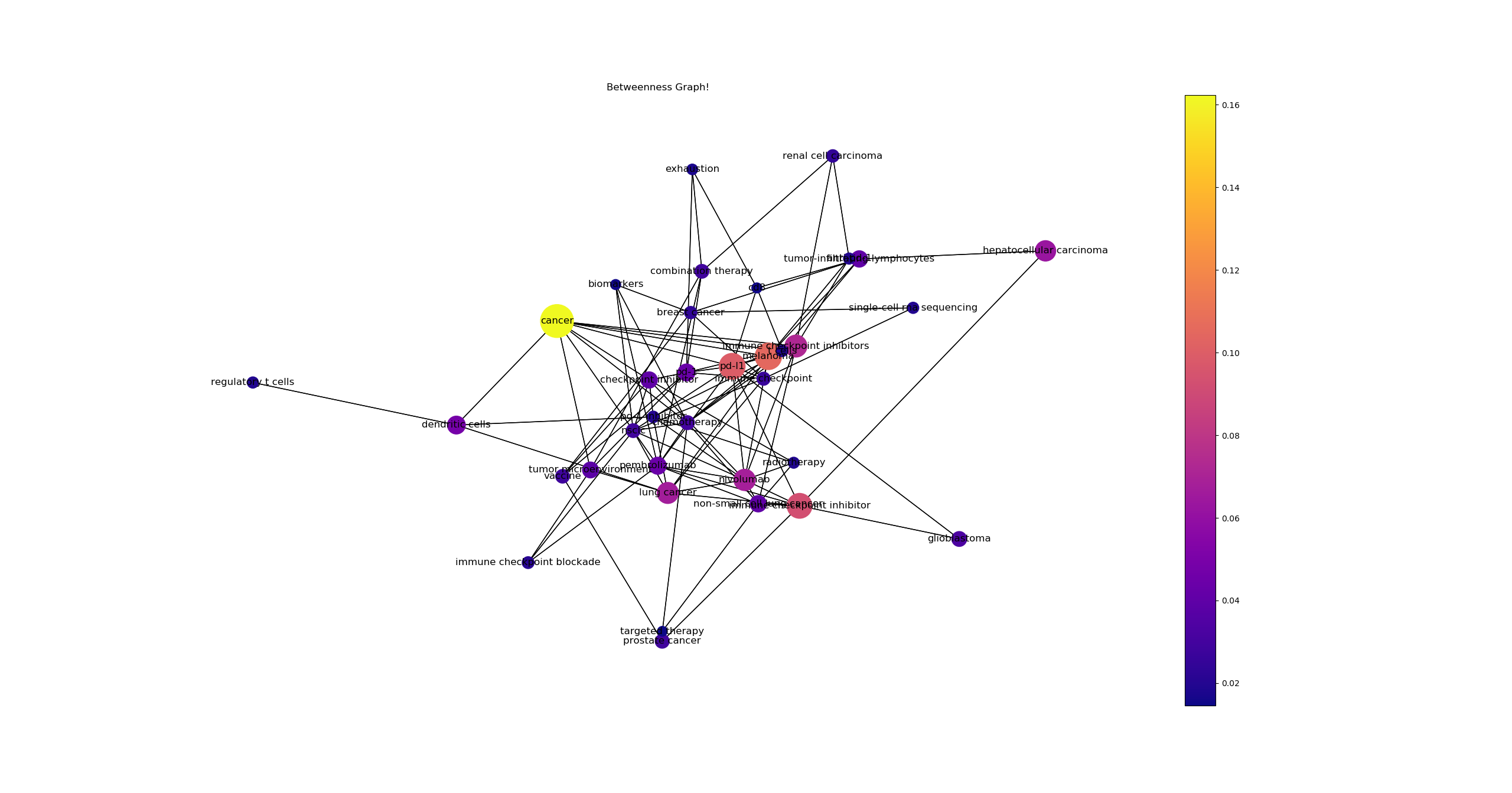
- 사용 데이터 셋 : 3605건의 논문 데이터
- 데이터 셋에서 100개의 논문 중 상위 5프로의 키워드를 기반으로 도출된 BC(Betweenness_centrality) 그래프
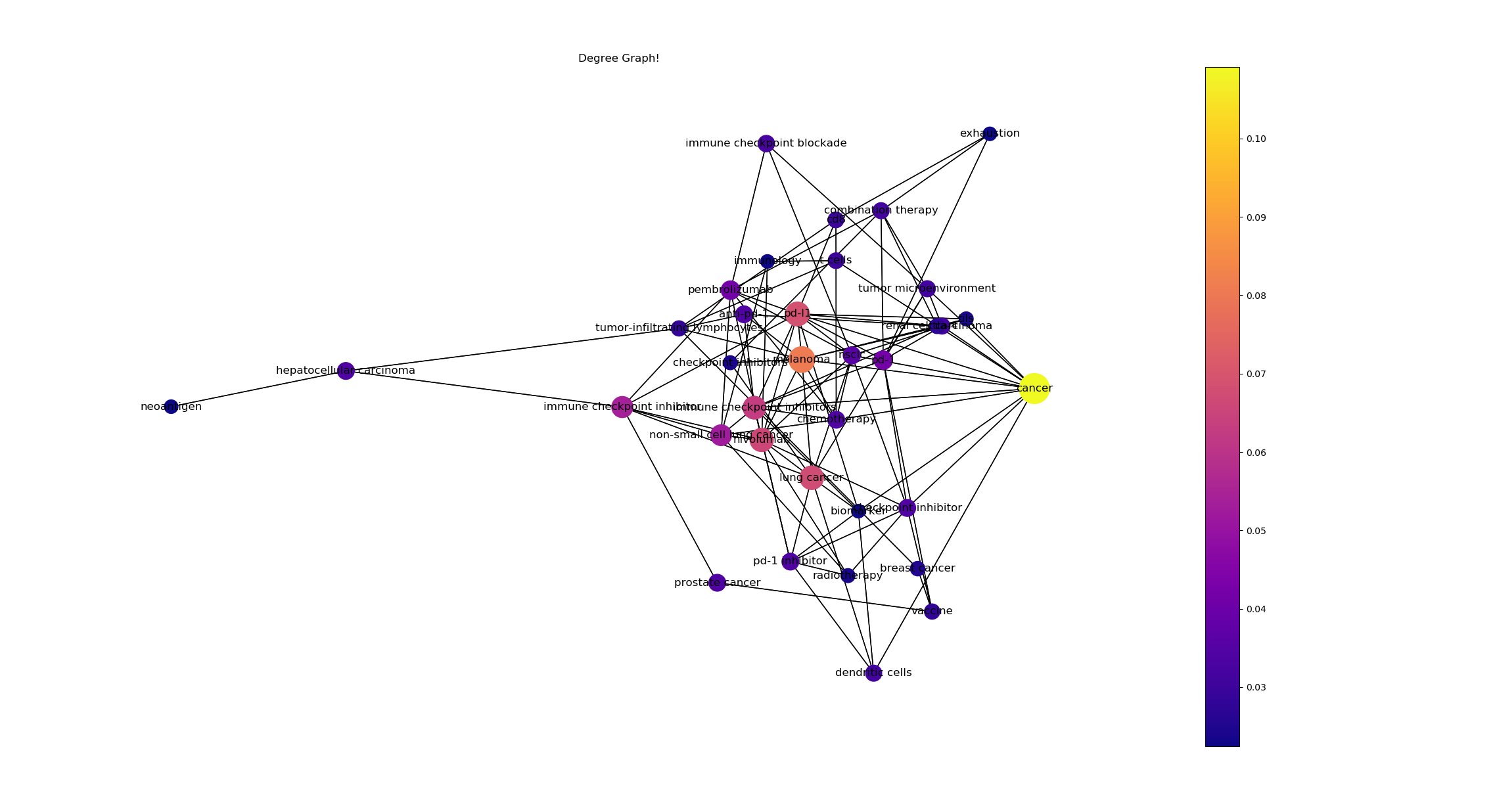
- 데이터 셋에서 100개의 논문 중 상위 5프로의 키워드를 기반으로 도출된 DC(Degree_centrality) 그래프
더 나아가기
시각화를 조금 더 정교하고 멋지게 하고 싶다면 Gephi를 사용하면 된다. Gephi는 JAVA를 기반으로 한 오픈소스 플랫폼이다. Gephi를 사용하면 기본적인 중심성 추출뿐만 아니라 클러스터링, PageRank, HITS도 쉽게 할 수 있다.
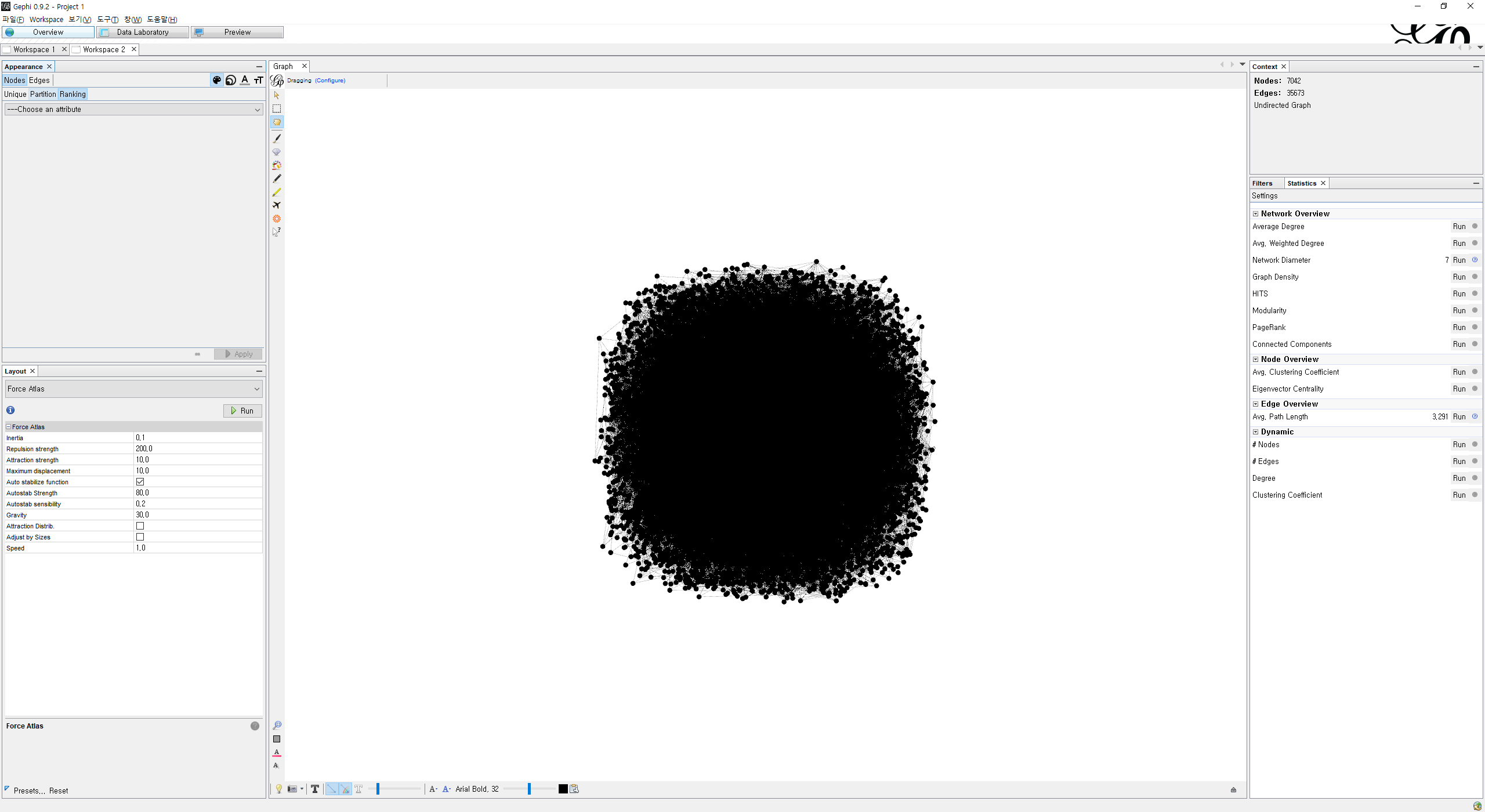
데이터 셋을 networkx를 이용하면 Gephi에서 사용가능한 확장자로 뽑아낼 수 있다. Gephi에서 사용가능한 파일 확장자는 .gexf이다.
.gexf 파일이 준비됐으면 Gephi를 설치하고 실행해서 데이터를 불러온다. 그러면 친히 노드와 엣지의 개수를 알아서 파악하고 위 사진처럼 끈끈히 모아준다.
(Gephi는 JAVA 기반 오픈소스 플랫폼이기 때문에 JRE(Java Runtime Enviromnet)가 반드시 설치되어 있어야 한다.)
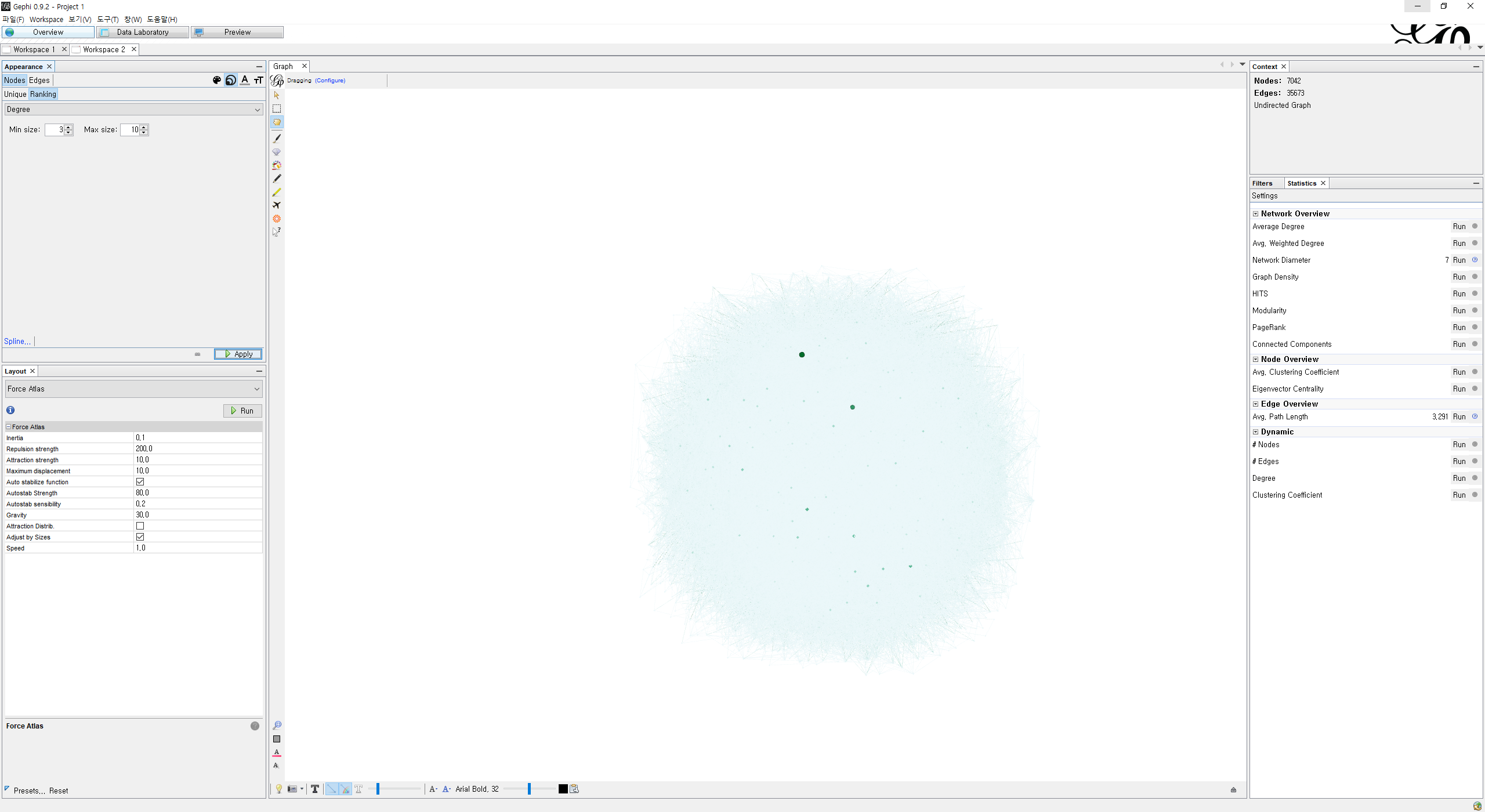
데이터 셋을 불러서 노드들과 엣지들이 생성됐다면 레이아웃(위 사진의 왼쪽 아래)을 설정한다. 여러 레이아웃이 있지만 나는 Force Atlas를 사용했다. 레이아웃을 적용하고 우측에 Statistics에서 여러 도구들 중 필요한 것을 선택(Run)한다. 기본적인 Degree, Betweenness을 사용하기 위해서는 Edge Overview의 하위 항목인 Avg. Path Length를 실행해야 한다.
실행하면 데이터 셋을 기반으로 분석한 결과를 리포팅 해 주며 왼쪽 상단의 영역에서 DC, BC, EC 등 중심성 계산하여 랭크, 파티셔닝 하는 것이 가능해 진다. 위 사진은 DC를 기준으로 랭크에 따른 노드의 색상을 변경한 것이다.
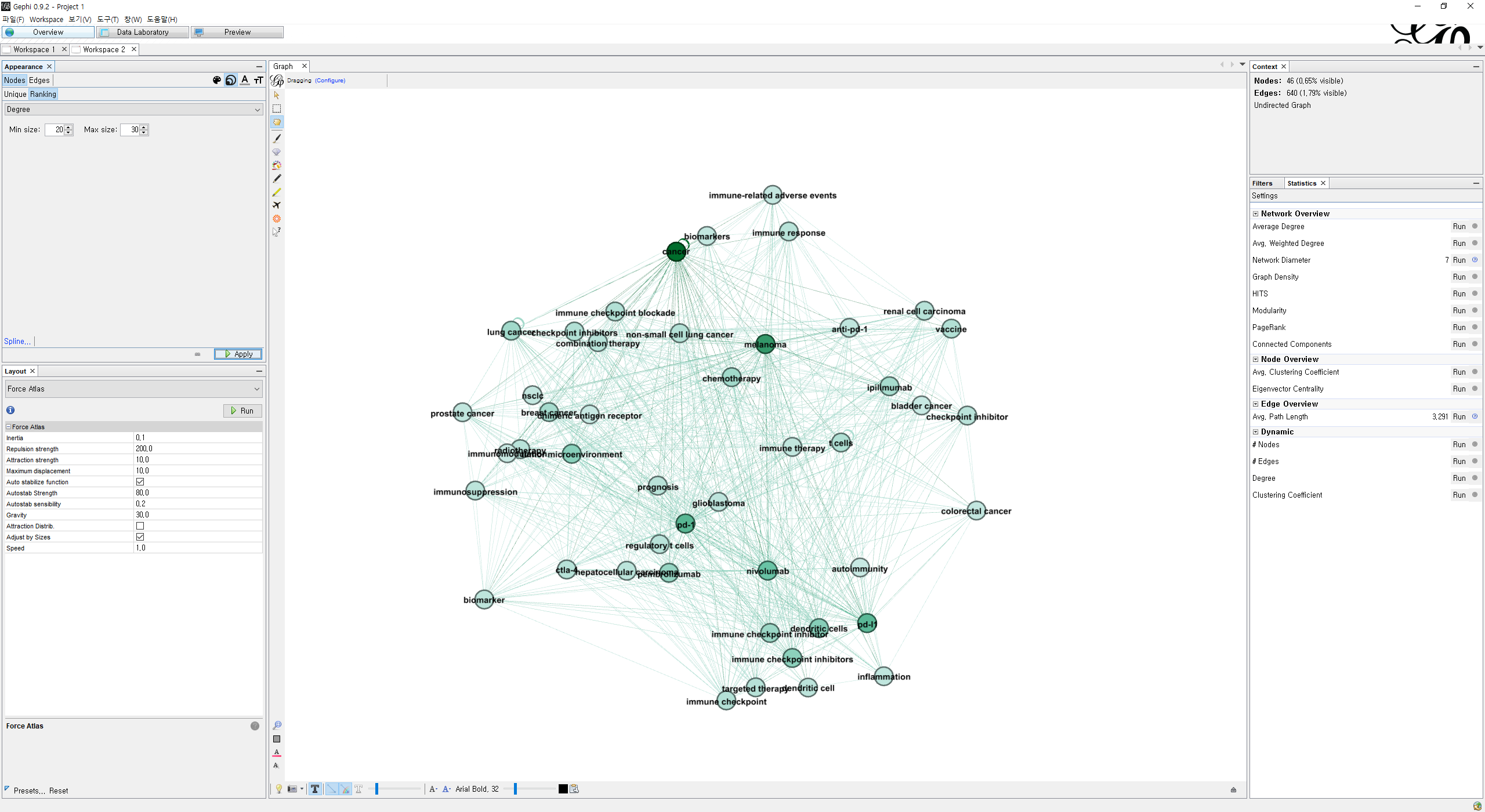
노드가 약 2만개 정도가 있었기 때문에 상위 노드들만 추출을 해야 시각화를 하는 것이 의미있다고 생각한다. 그래서 데이터를 필터링하였다. 위는 Edge의 개수가 190개 이상인 것들만 필터링하고 라벨링을 하여 노드들의 이름을 지어준 것이다.
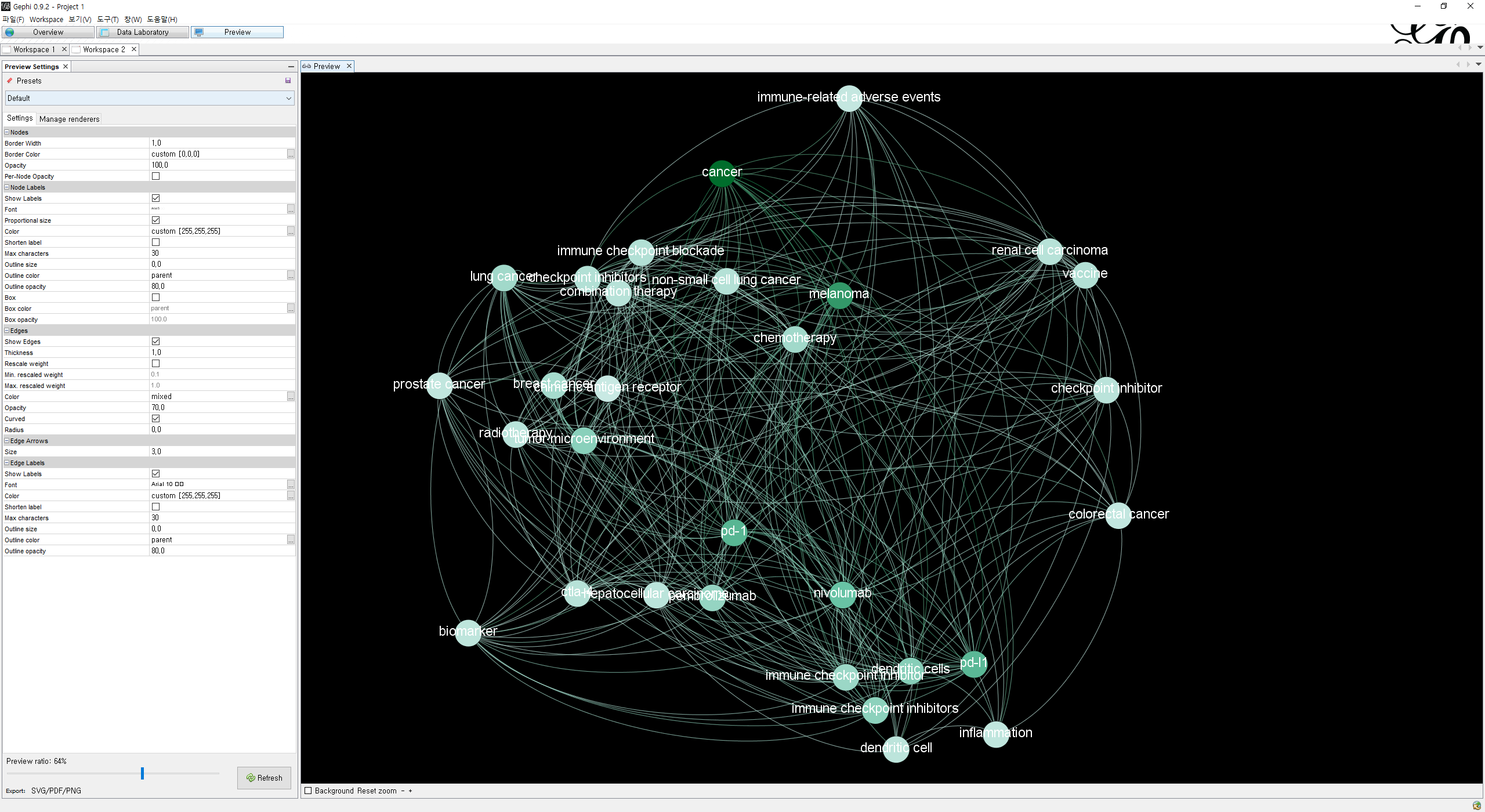
이제 데이터 순위화, 필터링도 했으니 상단의 Preview를 클릭해 만들어진 그래프를 자기 입맛에 맞게 바꿔야 될 시간이다. 나는 배경색을 검은색, 글자색은 하얀색으로 하여 몽환적인 느낌으로 그래프를 만들어 보았다. 이후에 만들어진 그래프는 PNG, SVG로 Export할 수 있다.